
Wenn es ums Programmieren geht, ist den meisten Programmierern klar, dass Code und Daten getrennt werden müssen. „Hartcodierung zu vermeiden“ ist in dieser Hinsicht die klare Richtlinie. Bei Excel hat sich diese Idee leider noch nicht durchgesetzt. Selbst wenn es um das VBA-Programmieren in Excel geht, verlassen sich viele Entwickler immer noch darauf, Code in riesigen XLSB-Dateien mit Daten zu vermischen. Dann fragen sie sich, warum die Leistung und die Wartbarkeit dieser Dateien so schlecht sind. In diesem Beitrag geht es jedoch nicht darum, VBA-Add-Ins für Excel zu schreiben (unter Verwendung von XLAM-Dateien).
In diesem Beitrag geht es darum, Daten und Berechnungslogik (anstelle von Code) in reinen Excel-Dateien getrennt zu halten. Grundsätzlich eine unverschämte Idee, da „Formeln ziehen“ und „Bereiche anpassen“ für die meisten Excel-Benutzer die normalen Reflexe sind, sobald sich die Eingabedaten ändern. Ich werde erklären, wie dynamische Matrixformeln dabei helfen, äußerst robuste Excel-Modelle zu erstellen, die sich automatisch an Änderungen in den Rohdaten anpassen.
Dementsprechend eignen sich die hier bereitgestellten Konzepte ideal für Excel-Berechnungen, die Bestand haben müssen, wie z.B. für Umfrageauswertungen oder Unternehmensberichte. Beiden ist gemeinsam, dass die Datenstruktur ziemlich ähnlich bleibt, während neue Umfragen bzw. neue Monate vor der Tür stehen.
Hinweis: Was Sie hier finden, ist meine persönliche Meinung basierend auf mehr als 10 Jahren Excel- und VBA-Erfahrung. Sie sind vielleicht anderer Meinung. Aber vielleicht lernst du ja trotzdem was dazu 😉
Klassische Möglichkeiten zum Erstellen eines Excel-Modells basierend auf Datendateien, z.B. aus Umfragetools oder Unternehmensanwendungen
Nehmen wir an, es gibt Rohdaten, die für verschiedene Berechnungen als Grundlage dienen. Diese Daten können eine Ergebnistabelle aus einem webbasierten Umfragetool oder aus Unternehmensanwendungen sein, wie z. B. eine Liste mit lieferantenbezogenen Ausgabenposten. Diese Daten könnten für eine Art Automatisierungsaufgabe dienen. Es könnte eine PowerPoint-Folienerstellung mit SlideFab sein. Es könnte aber auch ein VBA-Skript sein, das die Daten in mehrere Dateien zerlegt, z.B. eine Datei pro Lieferant. Eine solche Aufgabe ist der Ausgangspunkt für die hier vorgestellten Ideen.
Typische Ansätze zur Strukturierung von Logik und Rohdaten in einem Excel-Modell
Basierend auf meiner Erfahrung gibt es typischerweise drei Ansätze, wie ein Excel-Modell in dieser Situation erstellt werden kann.
Der einfache Ansatz: Berechnungen direkt in den Rohdaten durchführen
Viele Excel-Benutzer öffnen die Datendatei und fügen dann Spalten mit Formeln und Datenverweisen dort hinzu, wo immer dies erforderlich ist. Erfahrene Benutzer wissen zudem, dass das Hinzufügen von Spalten nur am linken und rechten Ende der Originaldaten klug ist. Wenn neue Rohdaten vorhanden sind, fügen sie diese dann einfach an der Stelle ein, an der sich die alten Daten befanden. Wenn sich die Anzahl der Zeilen ändert, ziehen sie die Formeln nach unten.
Der mittlere Ansatz: Einen separater Bereich für die Rohdaten (Staging Area) verwenden
Einige Excel-Benutzer erstellen zu Berechnungszwecken eine Excel-Arbeitsmappe, die eine Art „Staging-Bereich“-Arbeitsblatt enthält, in das Rohdaten vorab eingefügt werden können. Dann befinden sich die Berechnungen auf separaten Blättern, die sich auf diesen Bereich beziehen. Dies ist keine so schlechte Idee, da es die Daten weiter von der Logik (also von den Formeln) trennt. Dies ist sauberer als der einfache Ansatz, da es das Auffinden der Bereiche mit Rohdaten erleichtert.
Der fortgeschrittene Ansatz: Die Rohdaten in Excel-Tabellen separieren
Eine Minderheit von Excel-Benutzern folgt möglicherweise der Idee des mittleren Ansatz, verwendet jedoch Excel-Tabellen als Staging-Bereiche. Dies ist dahingehend nützlich, da es lesbare Formeln ermöglicht, die auf Tabellen- und Spaltennamen statt auf gewöhnlichen Arbeitsblatt- und Zellenadressen basieren. Die Tabellen sorgen für eindeutige Spaltennamen. Darüber hinaus reduziert dieser Ansatz zu einem gewissen Grad die Notwendigkeit Formeln herunter zu ziehen.
All diesen Ansätzen ist gemeinsam, dass sie Daten und Berechnungslogik in eine Excel-Arbeitsmappe vermischen. Selbst ein ganz nüchtern und robust strukturiertes Excel-Modell kann diesen Nachteil nicht vermeiden. Dementsprechend müssen diese Excel-Modelle nicht immer schlecht sein, aber es gibt noch Luft nach oben. Wenn Sie sich die meisten Beispiele ansehen, die hier auf SlideFab.com bereitgestellt werden, werden Sie außerdem feststellen, dass sie dem fortgeschrittenen Ansatz folgen. Dies war der beste Ansatz, den ich mir bisher ausgedacht habe, solange nicht noch zusätzlich VBA verwendet werden soll bzw. darf.
Schauen wir uns etwas Anderes, aber Verwandtes an: Datenverknüpfungen.
Was ist das Problem mit Excel-Datenverknüpfungen?
Das versehentliche Verknüpfen externer Excel-Dateien passiert recht häufig: Benutzer kopieren und fügen Formeln zwischen zwei Arbeitsmappen ein und plötzlich gibt es eine Verknüpfung: Die eingefügte Formel verweist nicht nur auf Arbeitsblätter und Bereiche, sondern auch auf die ursprüngliche Arbeitsmappe. Häufig ist es müßig, diese externen Verknüpfungen aufzuspüren und wieder los zu werden.
Wenn ich sehe, dass Benutzer Links zu anderen Excel-Dateien verwenden, dann erstellen sie oft hier und da einen Link zu bestimmten Zellen oder Bereichen in einer anderen Arbeitsmappe. Das funktioniert. Aber es ist ziemlich anfällig, da Änderungen an verknüpften Daten möglicherweise nicht in der verknüpften Arbeitsmappe widergespiegelt werden. Dementsprechend war ich kein Fan eines solchen Excel-Modellierungsansatzes. Meiner Meinung nach ist es in den meisten Situationen eine eher schlechte Praxis. Verstreute externe Verknüpfungen in einer Arbeitsmappe können ziemlich chaotisch werden.
Aber bevor wir Verbesserungsideen zu externen Excel-Datenverknüpfungen diskutieren, gibt es eine erwähnenswerte neue Excel-Funktionalität. Die meisten der erfahrenen Excel-Benutzer, die ich kenne, waren sich dieser Formeln bisher nicht bewusst. Hier macht also eine kurze Zusammenfassung Sinn.
Was sind dynamische Matrixformeln und warum sind sie so praktisch?
Microsoft führte im September 2018 Dynamische Felder und dynamische Matrixformeln (Dynamic Arrays und Dynamic Array Formulas) ein. Sie führten das sogenannte „Überlaufen“ für Formeln ein. Das bedeutet, dass eine Formel jetzt auf einen ganzen Bereich verweisen kann, wo sie zuvor nur eine einzelne Zelle erwartet hatte. In diesen Situationen kann eine einzelne Formel jetzt nicht nur die erste Zelle, sondern auch die anderen berücksichtigen. Das Berechnungsergebnis „schwappt“ auch auf andere Zellen über. Eine ziemlich künstliche Beschreibung, ich weiß. Unten sind einige Beispiele, um etwas mehr Licht auf ihre Funktionsweise zu werfen.
Das allein ist schon ganz nett, aber es wird noch besser: Excel erlaubt es, Formeln auf den Überlauf-Bereich zu referenzieren – nicht nur auf die Zelle, die die Formel enthält. Und wenn sich der Überlauf-Bereich ändert, spiegeln alle Referenzierungsformeln dies ohne manuellen Eingriff wider.
Betrachten wir ein einfaches Beispiel für dynamische Matrixformeln
Der „alte Stil“-Formelansatz erfordert eine eindeutige Formel pro Spieler (Spalten E und F), der „Überlauf-Stil“ mit dynamischen Matrixformeln erfordert nur eine Formel für alle Spieler (Spalten G und H). Auch wenn es auf dem Screenshot nicht zu sehen ist: Der Bereich G4:G10 ist leer. Die Ergebnisse laufen von G3 nach unten über, da es Bereiche anstelle von Zellen summiert. Beachten Sie auch das # am Ende der Formel =SUM(G3#) in Zelle H11. Dieser Hashtag stellt sicher, dass hier der gesamte Überlaufbereich (also G3:G10) verwendent wird (mehr zur #-Notation folgt).
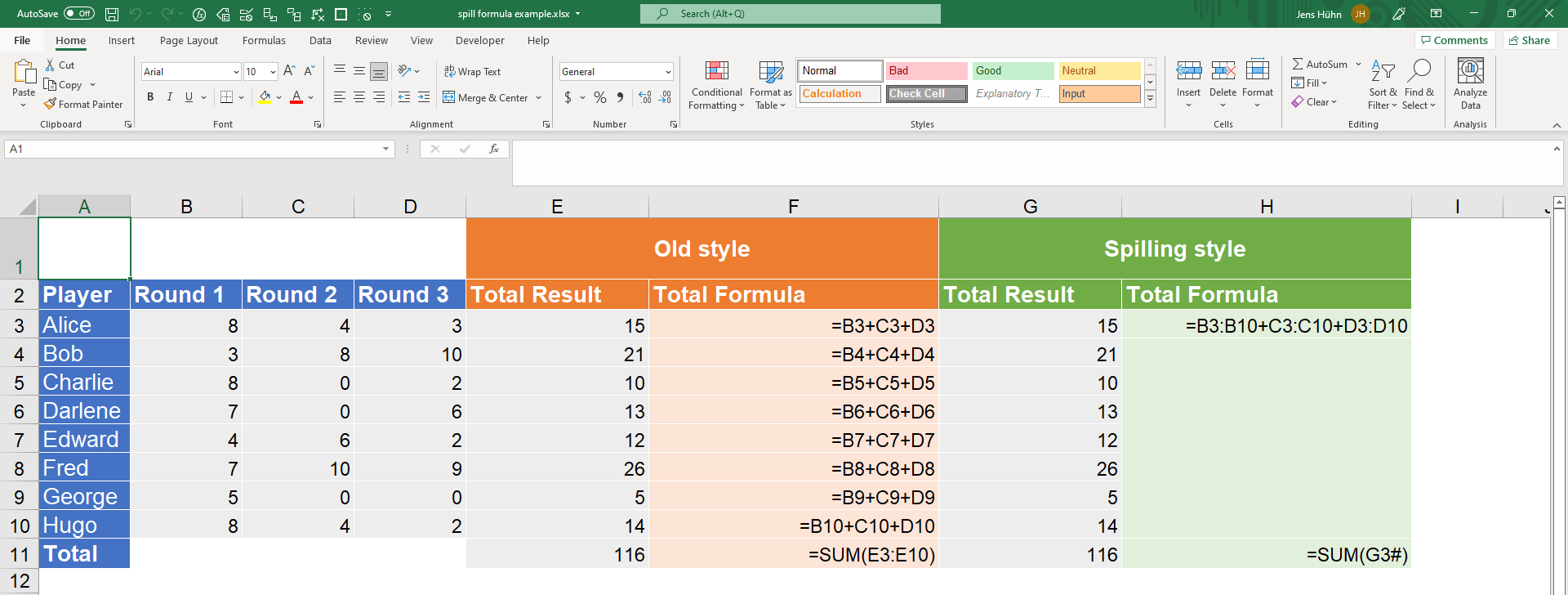
Zusätzlich zu diesem Überlaufverhalten sind einige neue Funktionen verfügbar, die die Arbeit mit Excel viel einfacher machen als zuvor. So sind zum Beispiel neue Funktionen wie SORTIEREN, EINDEUTIG oder FILTER enorm nützlich. Dies liegt an der enormen Arbeitsersparnis, die sie mit sich bringen (z. B. das Schreiben von Excel-Formeln oder das Programmieren von VBA), um die gleiche Funktionalität mit den althergebrachten Formeln zu verwirklichen. Diese neuen Formeln sind zentral, wenn es um die Entwicklung robuster Excel-Modelle für Automatisierungsaufgaben geht.
Ein weiteres Beispiel gibt einen Vorgeschmack auf die Leistungsfähigkeit von dynamischen Matrixformeln
Der folgende Screenshot zeigt ein weiteres Beispiel, das auf dem vorherigen basiert. Es veranschaulicht, wie man die Top 3 Spieler mit ihren Gesamtergebnissen in der richtigen Reihenfolge extrahiert. Und das alles ist mit nur einer Formel möglich. Eine kurze Erklärung dieser Formel in K3: SORTIERENNACH (SORTBY) wird verwendet, um den Bereich A3:E10 nach Werten des Gesamtergebnisbereichs E3:E10 absteigend zu sortieren. INDEX wird dann verwendet, um die obersten 3 Zeilen mit TRANSPONIEREN({1,2,3}) (TRANSPOSE) und Spalten für Spielername und Gesamtergebnis mit {1,5} auszuwählen. Die Zellen K4, K5, L3, L4, L5 haben keine Formel.
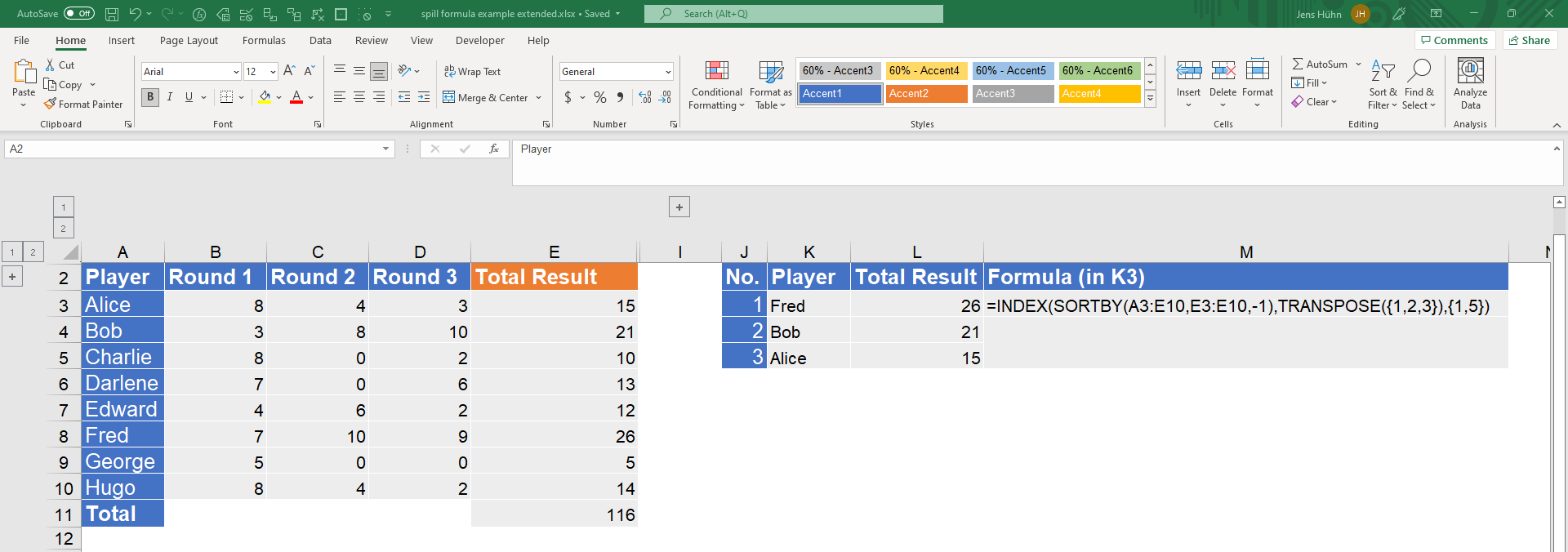
Es ist leicht zu verstehen, dass klassische Excel-Funktionen im Vergleich viel schwächer sind. Mehrere Berechnungsbereiche würden dieses Ergebnis Schritt für Schritt berechnen.
How to link Excel data files in a smart way using Dynamic Array Formulas?
Wie oben erläutert, bringt das bloße Verknüpfen einiger externer Bereiche in anderen Arbeitsmappen keinen Fortschritt, es ist sogar eher nachteilig. Viel besser ist es, wenn der gesamte externe Datenbereich auf einem Arbeitsblatt mit dynamischen Matrixformeln verknüpft wird. Aber nicht auf eine brutale Art und Weise wie eine 1:1048576-Referenz, die im Grunde alle Werte aus dem externen Arbeitsblatt zieht. Eine solche Verknüpfung wäre wirklich schlecht, da diese aufgrund der Verknüpfung von abertausenden leeren Zellen ohne jeglichen Mehrwert viel Leistung kostet. Schauen wir uns also einen intelligenteren Weg an.
Die Idee ist, nur den Bereich zu verknüpfen, in dem sich wirklich Daten befinden. Mit einer dynamischen Matrixformel wird es sogar möglich, dass Änderungen in der Datenmenge (seien es mehr oder weniger Zeilen oder Spalten) automatisch berücksichtigt werden. Wie kann dies geschehen? Der Einfachheit halber gehen wir davon aus, dass die Daten in A1 beginnen und Spaltenüberschriften in Zeile 1:1 und Zeilenüberschriften in den Spalten A:C haben. Der Rest dieses Artikels verwendet einige exemplarischen Finanzdaten. Diese Daten enthalten vier Kennzahlen (d. h. Umsatz, Kosten der verkauften Waren (COGS), Marge und Einheiten) für Länder, die zwischen Januar 2020 und Dezember 2021 in Regionen gruppiert sind.
Die Beispieldaten sehen wie folgt aus:
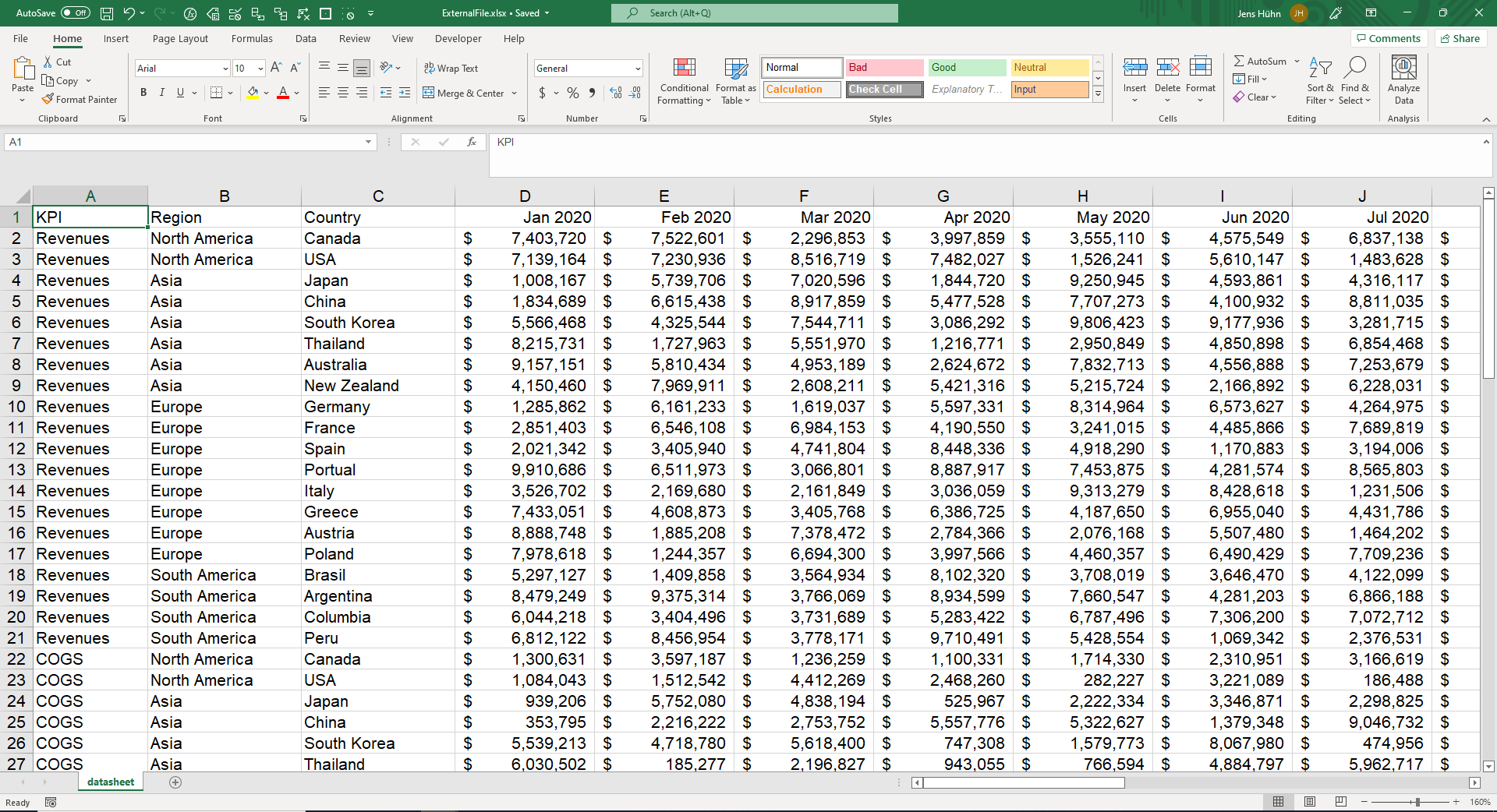
Zunächst stellt sich die Frage: Wie viele Zeilen und Spalten gibt es?
Glücklicherweise wird diese Frage durch die folgende Formel beantwortet:
=BEREICH.VERSCHIEBEN('[ExternalFile.xlsx]datasheet'!$A$1,0,0,
VERWEIS(2,1/('[ExternalFile.xlsx]datasheet'!$A:$A<>""),
ZEILE('[ExternalFile.xlsx]datasheet'!$A:$A)
),
VERWEIS(2,1/('[ExternalFile.xlsx]datasheet'!$1:$1<>""),
SPALTE('[ExternalFile.xlsx]datasheet'!$1:$1)
)
)
Die Idee dieser Formel besteht darin, BEREICH.VERSCHIEBEN zu verwenden, beginnend in A1 des externen Arbeitsblatts, um sich dann an die Größe des tatsächlich verwendeten Bereichs anzupassen. Hierfür werden die letzten Einträge dann in Zeile 1 bzw. Spalte 1 gesucht. Diese letzten Einträge werden mit den Funktionen VERWEIS–ZEILE/SPALTE gefunden.
Das Ergebnis dieser Formel ist ein Bereich, der alle Daten im externen Arbeitsblatt abdeckt. Aufgrund des Überlaufverhaltens zieht diese Formel alle externen Daten und fügt sie in das Arbeitsblatt ein.
Als Randnotiz: Die BEREICH.VERSCHIEBEN-Formel wird manchmal mit ANZAHL2 kombiniert, um die Anzahl der nicht leeren Einträge zu erhalten. Wenn keine Leerzeichen vorhanden sind, funktioniert dies auch. Wo dies der Fall ist, wird die Zeilenanzahl bzw. Spaltenanzahl unterschätzt. Dementsprechend ist die obige Formel die empfohlene Version.

Um genau zu sein, lässt sich die Idee von oben noch etwas verbessern: Anstatt alles ab Zelle A1 zu verlinken, ist es klüger, Spaltenüberschriften und Daten in separate Formeln dieser Art zu trennen.
Die Formel für die Spaltenüberschrift geht also in datasheet_loading_improved!A1. Es funktioniert auf ähnliche Weise, berücksichtigt jedoch nur die erste Zeile des verknüpften Arbeitsblatts:
=BEREICH.VERSCHIEBEN('[ExternalFile.xlsx]datasheet'!$A$1,0,0,,
VERWEIS(2,1/('[ExternalFile.xlsx]datasheet'!$1:$1<>""),
SPALTE('[ExternalFile.xlsx]datasheet'!$1:$1)
)
)
Die Daten-Verknüpfungsformel geht in datasheet_loading_improved!A2 und beginnt einfach mit der Referenzierung unterhalb der Zeile mit den Spaltenüberschriften wie folgt:
=BEREICH.VERSCHIEBEN('[ExternalFile.xlsx]datasheet'!$A$2,0,0,
VERWEIS(2,1/('[ExternalFile.xlsx]datasheet'!$A:$A<>""),
ZEILE('[ExternalFile.xlsx]datasheet'!$A:$A)
) - 1,
VERWEIS(2,1/('[ExternalFile.xlsx]datasheet'!$1:$1<>""),
ZEILE('[ExternalFile.xlsx]datasheet'!$1:$1)
)
)

Was ist also der Vorteil einer solchen Verknüpfung von Daten mit dynamischen Matrixformeln?
Es gibt ein paar Vorteile dieses Ansatzes.
- Bei der Verknüpfung aller Rohdaten ist es möglich, sämtliche Daten von der Logik zu trennen. Die Daten sind also in einer eigenen Datei (oder mehrere Dateien, abhängig von der Aufgabenstellung) und die Logik (also Formeln und Strukturen) in einer anderen. Wenn es also neue Daten gibt, müssen nur die Verknüpfungen zwischen der „logischen“ Excel-Arbeitsmappe und der neuen Datendatei (den Datendateien) aktualisiert werden. Auch wenn Änderungen an der logischen Excel-Arbeitsmappe vorgenommen werden, ist es kein Problem, die Daten darin zu aktualisieren. Auch hier müssen dann nur die Datenverknüpfungen zu den Rohdaten angepasst werden.
- Die verknüpften Daten können unter einer neuen Arbeitsblattadresse gefunden werden, die die Überlauf-Notation verwendet und mit einem Hashtag endet, z.B.
Sheet1!A1#. Dieser Bereich hat nach obiger Formel genau die richtige Größe. Daher ist es sehr praktisch, auf diesen Bereich zu verweisen. Es werden keine Zeilen oder Spalten ausgelassen. Keine überflüssigen Zeilen und Spalten reduzieren die Leistung. - Dieser Ansatz ist sehr sauber. Es gibt nur 1 Überlauf-Formel, die auf externe Daten verweist (oder vielleicht 2, wenn Kopfzeile und Daten separat verknüpft sind). Keine Berechnungslogik wird direkt auf externe Daten verweisen, sondern auf diese verknüpfenden Datenbereiche. Dies macht Formeln viel besser lesbar, wenn sie keine Pfad- und Dateinameninformationen enthalten. Und noch besser, in Fällen, in denen ein Verknüpfung bricht, muss nicht überall nach
#REF!gesucht werden, sondern nur bei den entsprechenden 1 bis 2 Formeln pro externem Arbeitsblatt. Dementsprechend wird es ziemlich einfach sein, defekte Links zu reparieren.
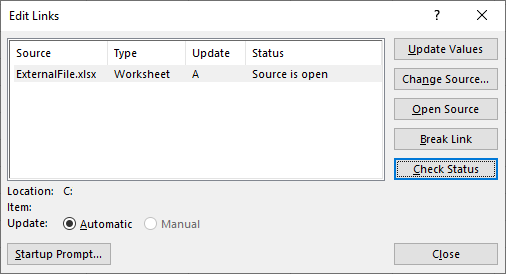
Wie geht man mit dem überlaufenden Excel-Bereich um, der auf die externen Daten verweist?
Durch die Verknüpfung der externen Daten ergeben sich vielfältige Möglichkeiten. Was die nächsten Aufgaben sind, hängt von den Daten und den Zielen ab. Glücklicherweise gibt es ein paar Muster, die in vielen Situationen nützlich sind. Die nächsten Abschnitte werden zumindest einige der Möglichkeiten beleuchten.
Finden der richtigen Spaltennummer anhand des Spaltennamens
Es kann vorkommen, dass die externe Datendatei eine andere Spaltenreihenfolge hat. Oder vielleicht gab es eine Formel, die einen berechneten Spaltennamen erhielt. Oder vielleicht kommen jeden Monat neue Spalten hinzu. Die Frage ist also: Wie bekommt man die Spaltendaten für die weitere Bearbeitung.
Da davon ausgegangen wird, dass sich die Spaltenüberschrift und die Daten in zwei separaten Überlauf-Bereichen befinden, ist die Formel zum Erhalten der Spaltennummer ziemlich einfach zu erstellen.
=XVERWEIS(ColumnNumbers[[#Headers],[KPI]],datasheet_loading_improved!$A$1#)
Dies ist ein einfaches Nachschlagen der Spaltenüberschrift (hier adressiert über eine Excel-Tabelle ColumnNumbers[[#Headers],[KPI]]) innerhalb des Überlauf-Bereichs für die Kopfzeile datasheet_loading_improved!$A$1#.
Eine Excel-Tabelle, in der die Spaltennummer für die weitere Verwendung leicht zugänglich ist, macht Sinn:
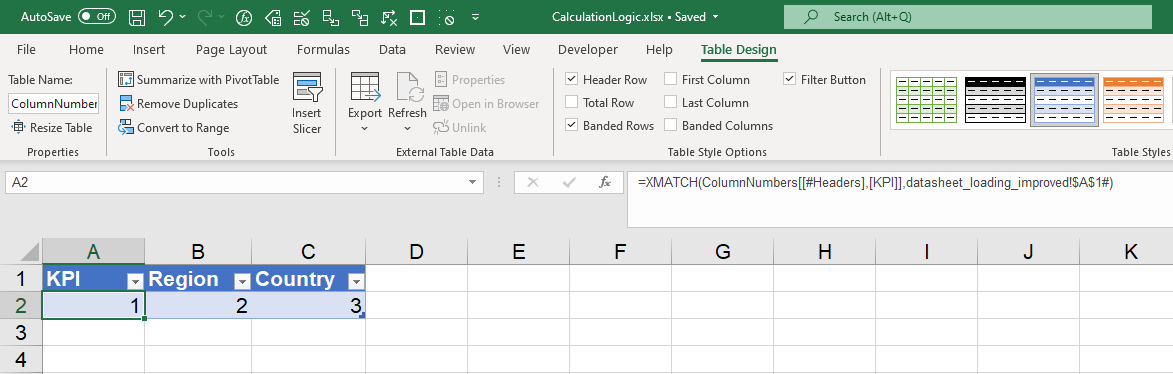
Abrufen einer eindeutig sortierten Liste von Einträgen für die Aggregation oder Iteration
Sobald die Spaltennummer – wie zuvor erläutert – klar ist, lässt sich eine komplette Spalte mit der INDEX-Funktion zu extrahieren. Zur einfacheren Handhabung ist es sinnvoll, ein Arbeitsblatt zu erstellen, das alle eindeutigen Listen enthält, die für Aggregations- oder Iterationszwecke verwendet werden sollen. Im Beispiel ist es sinnvoll, eine eindeutige Liste der KPI-Namen und der Regionsnamen zu haben.
=UNIQUE(INDEX(datasheet_loading_improved!A2#,,ColumnNumbers[KPI]))
Die INDEX-Funktion gibt die gesamte KPI-Spalte aus dem Datenbereich zurück, wobei die Spaltennummer verwendet wird, wie sie in der ColumnNumbers-Tabelle definiert ist, siehe oben. Im Gegensatz zu klassischen Excel-Formeln kann die INDEX-Funktion nun mehr als eine einzelne Zelle zurückgeben. Wenn der Zeilenparameter leer gelassen wird (das doppelte Komma, das nichts dazwischen hat, ist kein Tippfehler), werden dementsprechend nur alle Zeilen zurückgegeben. Anschließend entfernt die EINDEUTIG-Funktion alle Duplikate. Auch wenn es hier nicht gezeigt wird: Wie eine SORTIEREN-Funktion hier ergänzt wird, dürfe nicht so schwierig sein.

Versorgen von Dropdown-Listen mit überlaufenden dynamischen Matrixformlen
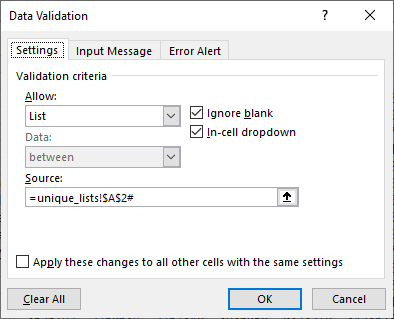
In der Tat sind Dropdown-Listen nicht erforderlich, um ein robustes Excel-Modell für die Automatisierung zu erstellen. Sie machen das Testen und die manuelle Nutzung jedoch deutlich komfortabler. Glücklicherweise leisten die oben definierten eindeutigen Listen eine hervorragende Arbeit, wenn es darum geht, Dropdown-Listen auf dynamische Weise zu füllen. Ein Dropdown mit dynamischen Längen zu haben, erfordert nicht mehr die umständlichen OFFSET/COUNTA-Funktionskonstrukte.
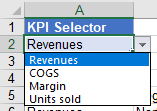
Beispielsweise ist das Erstellen eines dynamischen KPI-Selektors sehr einfach (beachten Sie das # am Ende der Formel):
Werte aus dem verknüpften Datenarbeitsblatt mit dynamischen Matrixformeln extrahieren
Daten aus dem Überlauf-Bereich zu erhalten ist recht anspruchsvoll, um es nicht gleich als „umständlich“ zu bezeichnen. Der Mehrwert ist jedoch, dass Formeln, die sich auf diese Überlauf-Bereiche beziehen, sehr robust sind und keine Wartung erfordern, sobald sich die Eingabedaten ändern, wie bereits oben erläutert.
Die folgenden exemplarischen Situationen und deren Lösungen sollen einige Anregungen geben.
Extrahieren von Zellen oder Bereichen mit der FILTER-Funktion
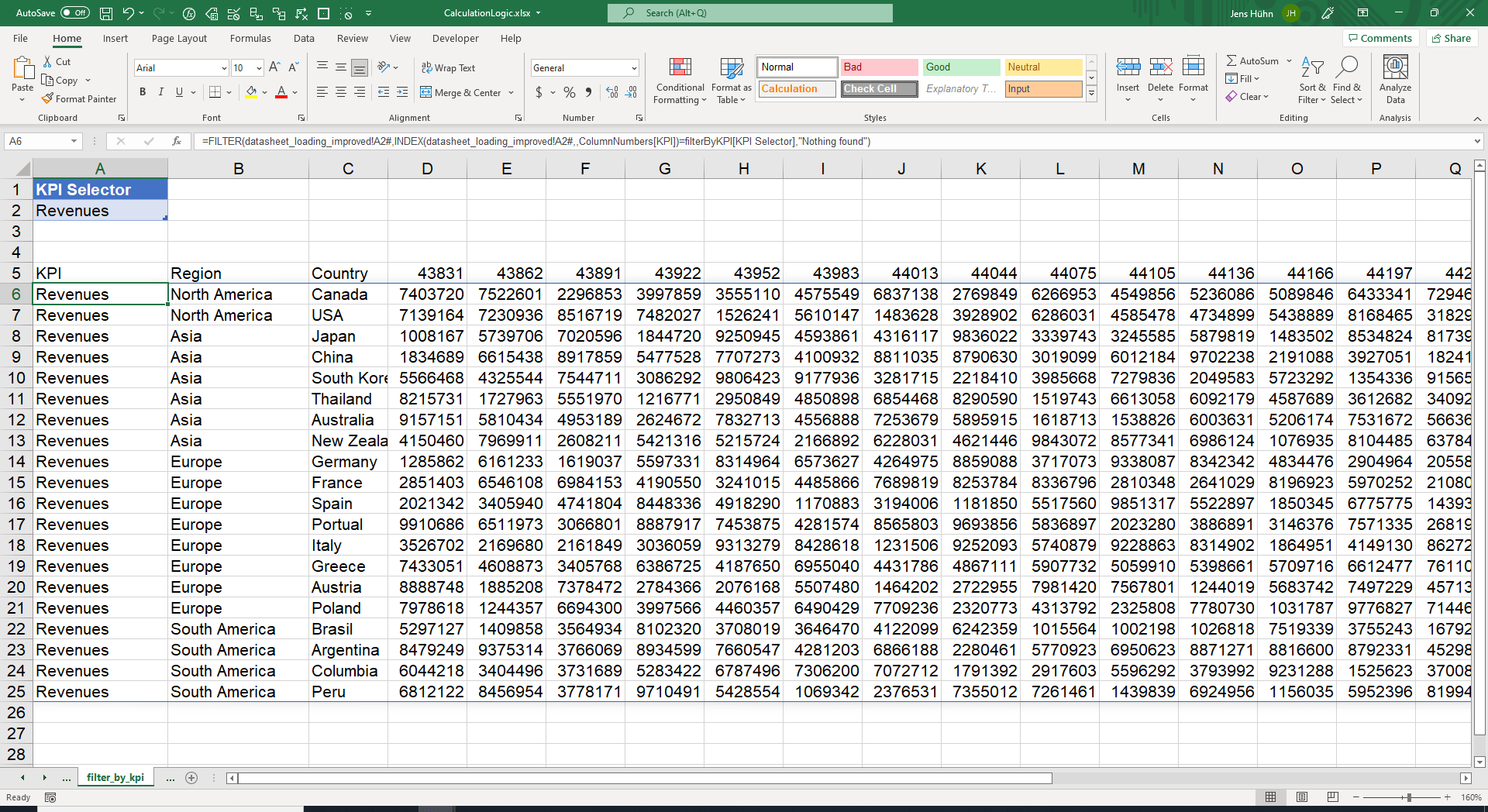
Wenn nur bestimmte Zeilen oder Spalten aus dem Überlauf-Bereich benötigt werden, leistet die FILTER-Funktion hervorragende Arbeit. In ihrer Grundform gibt sie die Zeilen/Spalten aus dem bereitgestellten Bereich zurück, die eine bestimmte Bedingung erfüllen. Wenn beispielsweise nur Umsätze angezeigt werden sollen, ist dies für die FILTER-Funktion gar kein Problem.
=FILTER(
datasheet_loading_improved!A2#,
INDEX(datasheet_loading_improved!A2#,,ColumnNumbers[KPI])=filterByKPI[KPI Selector],
"Nothing found"
)
In diesem Beispiel nimmt die Filterfunktion als ersten Parameter den überlaufenden Datenbereich und filtert ihn im zweiten Parameter, indem sie die Kennzahlen-Spalte (KPI) INDEX(datasheet_loading_improved!A2#,,ColumnNumbers[KPI]) mit der ausgewählten Kennzahl filterByKPI[KPI Selector] vergleicht. Der dritte Parameter schließlich enthält eine Standardmeldung, wenn überhaupt nichts gefunden wird.
Zweidimensionales Aggregieren von Daten mithilfe der MAKEARRAY- und LAMBDA-Funktion
Eine ziemlich herausfordernde Aufgabe besteht darin, dynamische Matrixformeln zu verwenden, um Daten zweidimensional zu aggregieren, ohne die Formel zu ziehen. Zum Beispiel beim Aufsummieren der Werte pro KPI für alle Monate auf einmal. Während es ziemlich einfach ist, eine horizontale Kopfzeile mit den Monaten und eine vertikale Kopfspalte mit den eindeutigen KPIs zu überspannen, ist die eigentliche Berechnung nicht so einfach. Tatsächlich müssen sowohl die neuen MAKEARRAY– als auch die LAMBDA-Funktionen eingebracht werden.
=MAKEARRAY(
ZEILEN(A3#),
SPALTEN(B1#),
LAMBDA(
r,
c,
SUMME(
WENNFEHLER(
datasheet_loading_improved!A2# *
--(INDEX(datasheet_loading_improved!A2#,,ColumnNumbers[KPI])=INDEX(A3#,r)) *
--(datasheet_loading_improved!A1#=INDEX(B1#,1,c))
,0)
)
)
)
Die MAKEARRAY-Formel spannt über die ersten beiden Parameter ZEILEN(A3#) und COLUMNS(B1#) ein Array mit der benötigten Anzahl an Zeilen und Spalten auf.
Der dritte Parameter von MAKEARRAY ist für die LAMBDA-Funktion und liefert die Anzahl der Zeilen r und Spalten c an ihre ersten beiden Parameter.
Der dritte Parameter von LAMBDA übernimmt hier die SUMME-Funktion, um eine SUMMEWENNS-Berechnung zu simulieren. Das Produkt hat dabei drei Faktoren:
- Den Datenbereich
datasheet_loading_improved!A2# - Die Zeilenbedingung
--(INDEX(datasheet_loading_improved!A2#,,ColumnNumbers[KPI])=INDEX(A3#,r)) - Die Spaltenbedingung
--(datasheet_loading_improved!A1#=INDEX(B1#,1,c))
Die Bedingungen in 2) und 3) ergeben 1 oder 0, wenn sie zutreffen oder nicht. Die SUMME zählt also einen Wert, wo sie zutreffen, und 0, wo eben nicht. Außerdem verwenden die Formeln in 2) und 3) die Zeilennummer r und die Spaltennummer c mit INDEX, um die Bedingungswerte zu erhalten.

Wie geht man mit überlappenden Überlauf-Bereichen um?
Die Überlaufbereiche nehmen so viel Platz wie erforderlich ein. Wenn die Rohdaten zunehmen, wachsen auch die Überlaufbereiche. Dies kann zu Situationen führen, in denen sich Überlaufbereiche überlappen und der fiese #SPILL! Fehler auftritt. Die Überlegung, wie viel „Reserve“ zwischen den Berechnungsbereichen gelassen werden sollte, ist hier verlockend. Es folgt dem alten Konzept, Formeln von Zeile 1 bis 5.000 (oder die Zahl Ihrer Wahl) reichen zu lassen, da es unvorstellbar ist, dass es mehr Zeilen gibt. Aber wenn es doch mehr Zeilen gibt, werden die Formeln die Daten verfehlen. Die Alternative, die Formel manuell zu ändern, ist auch nicht so attraktiv. Viel Glück dabei in größeren Excel-Modellen, wo man hier und da leicht eine Formeländerung übersehen kann.
Es gibt nur eine robuste Lösung
In Situationen, in denen sowohl die Anzahl der Zeilen als auch die Anzahl der Spalten dynamisch sind, gibt es also nur eine robuste Lösung: Eine Berechnung pro Blatt, die theoretisch bis zu einer Million Zeilen und 16.384 Spalten abdecken kann. Komplexe, abhängige Berechnungen führen dann zu einer Reihe von Berechnungsblättern. Jedes dieser Blätter wird sehr ordentlich und schlank sein, da in den meisten Fällen nicht zu viele überlaufende Formeln erforderlich sein sollten. Daher wird die Benennung von Arbeitsblättern wichtig, um Verwirrung zu vermeiden. Aber damit wird die Berechnungslogik sehr sauber und stringent.
Aber keine Regel ohne Ausnahmen
- Es gibt auch Spilling-Formeln, die entweder in Zeilen oder in Spalten wachsen. Hier ist es viel einfacher, ein überschneidungsfreies Arbeitsblatt mit mehreren Berechnungen darauf zu strukturieren.
- Wächst ein „Haupt“-Überlaufbereich sowohl nach rechts als auch nach unten, dann gibt es links und oben Möglichkeiten für alle Arten von Berechnungen, die nicht in Richtung des „Haupt“-Überlaufbereichs überlaufen. Dies führt zu einer umgekehrten Richtung, in der Berechnungsschritte von rechts nach links bzw. von unten nach oben fließen. Dies ist sicherlich ungewöhnlich, vermeidet jedoch potenzielle Überschneidungen.
Was sind die Nachteile dieses Ansatzes?
Natürlich hat auch diese Medaille zwei Seiten. Während der Großteil des Artikels die Vorteile beschrieb, sollte hier auch Platz für die Nachteile sein:
- Das Verknüpfen externer Daten erfordert, dass die verknüpften Arbeitsmappen geöffnet sind. Dies kann unangenehm sein, wenn zu viele verknüpfte Excel-Dateien vorhanden sind.
- Die Verwendung von dynamischen Matrixformeln und der Überlauf-Mechanismus sind nicht so lesbar wie bei der Verwendung von Excel-Tabellen. Es ist eher wie beim klassischen Excel: Arbeitsblattnamen und -adressen erscheinen innerhalb der Formeln.
- Die Überlaufbereiche einer Formel geben nur die Werte, aber nicht die Formate zurück. Insbesondere fehlende Zahlenformate verursachen zusätzlichen Aufwand, z.B. indem Sie Formate manuell anwenden oder die
TEXT-Funktion dafür verwenden. - Die Modularität bei der Trennung von Daten und Berechnungslogik führt zu separaten Dateien. Einige Leute mögen das vielleicht nicht und bevorzugen stattdessen „schwere“ Excel-Dateien.
Verarbeitung der Berechnungsergebnisse der dynamischen Matrixformeln zur weiteren Verwendung
Achten Sie auf Zahlenformate
Nach dem Erstellen der Berechnungen ist es an der Zeit, sich Gedanken über die Darstellung der Ergebnisse zu machen. Dazu gehört natürlich auch die Zahlenformatierung. Da die Überlaufbereiche nicht ihr ursprüngliches Zahlenformat mit sich führen, ist es sehr sinnvoll, die TEXT-Funktion zu verwenden, um das gewünschte Zahlenformat zu übernehmen. Dies bewahrt auch die Überlauf-Idee, die leiden würde, wenn Bereiche manuell formatiert würden. Wenn dies aber doch gewünscht ist, wäre es gut, die gesamte Zeile oder Spalte zu formatieren, damit die Formateinstellungen nie ausgehen, sobald der Überlauf-Bereich zunimmt.
Erstellen von Diagrammen basierend auf Überlaufbereichen
Diagramme sind natürlich sinnvoll, um einen Einblick in die Ergebnisse zu geben. Da Diagramme keine dynamischen Matrixformeln unterstützen, hilft ein kleiner Trick: Es hilft, den Überlaufbereich in einen benannten Bereich (Named Range) zu packen. Dann können Diagramme auch die Überlauf-Funktionalität nutzen.
Zusammenfassung
Dieser Artikel gab einen ziemlich kurzen Überblick darüber, wie man eine robuste Excel-Arbeitsmappe erstellt. Die vorgestellten Konzepte bauen auf den neuen Excel dynamischen Matrixformeln (Dynamic Array Formulas) und einer Trennung von Berechnungslogik und Rohdaten auf. Diese Formeln trugen dazu bei, das Ziehen von Bereichen zu vermeiden, wodurch die Wartbarkeit aller Formeln im Excel-Modell verbessert wurde. Stattdessen passen sich diese neuen Formeln automatisch an Änderungen in den Rohdaten an, da ihr Überlaufbereich so viel Platz wie erforderlich einnimmt. Der Artikel ging nicht detailliert darauf ein, wie man eine SlideFab-Automatisierung erstellt. Dies wird in separaten Blogbeiträgen behandelt.
Natürlich stehen auch die in diesem Blogbeitrag gezeigten Beispieldateien zum Download bereit:
Selber machen oder Excel- und SlideFab-Dienste einkaufen
Ein persönlicher Kommentar zum Schluss: In diesem Blogbeitrag habe ich eine Fülle von Details meines Denkprozesses geteilt, wie ich robuste Excel-Modelle erstelle. Der Inhalt hier erfordert jedoch mit Sicherheit einen fortgeschrittenen Excel-Benutzer. Wenn Ihnen gefällt, was Sie hier sehen, aber nicht die Fähigkeiten oder die Zeit haben, es selbst zu bauen, wenden Sie sich bitte an uns. Das Erstellen komplexer Excel-Modelle – insbesondere, aber nicht ausschließlich für SlideFab – ist eines unserer Angebote.